
Blogi: Tekstinlouhintaratkaisujen hyödyntäminen terveystieteellisessä tutkimuksessa
Ihmisen luonnolliset tavat kommunikoida ovat moninaisia, monimutkaisia ja sisältävät suuren määrän tietoa. Ihmisen kirjoittama rakenteeton teksti kantaa suuren määrän sisällöllisiä, tyylillisiä, kielellisiä ja monia muita tulkintaan vaikuttavia tekijöitä. Ihminen voi helposti tunnistaa ja tulkita kirjoitettua tekstiä, mutta jos haluamme käyttää tekstinlouhintaa esimerkiksi kliinisen tiedon louhinnassa potilaskertomuksista, tulemme kohtaamaan lukuisia haasteita.
Ihmisen kirjoittaman tekstin prosessointi voi olla tietokoneelle erittäin haastavaa, sillä teksti voi sisältää tuhansia eri sanoja ja erimuotoisia sanoja, jotka muodostavat lauseita, kappaleita ja laajoja kertomuksia. Kukin lauseen sana voi epäsuorasti muuttaa toisen sanan merkitystä, mikä voi antaa lauseelle joko erittäin spesifin tai tulkinnanvaraisen merkityksen. Lause voi epäsuorasti vaikuttaa toisten lauseiden merkitykseen joko lauseen sisällön tai lausejärjestyksen vuoksi muuttaen tekstikappaleen tulkinnanvaraista merkitystä.
Ihmisten kirjoittamissa potilaskertomuksissa nämä kielelliset säännöt ovat oleellisia. Potilaskertomuksissa on sekä rakenteista dataa, kuten laboratoriokokeiden tuloksia että rakenteetonta dataa, kuten vapaamuotoista tekstiä. Siten potilaskertomuksissa on paljon kliinisesti merkittävää tietoa, jota voidaan käyttää kliinisessä tutkimuksessa tauteihin vaikuttavien tekijöiden tunnistamiseen ja sairauksien ennustamiseen. Kliinisesti merkittävän tiedon käsin louhiminen potilaskertomuksista on hidasta ja aikaa kuluttavaa, siksi tekstinlouhinnan automatisointi on tutkijoille houkutteleva ratkaisu.
Kehittyneillä tekstinlouhintaratkaisuilla olisi mahdollista poimia potilaskertomuksista lääkärien ja hoitajien muistiinpanoja, tautihistoriaa, lääkitystietoja, riskitekijöitä, ja monia muita kliinisesti merkittäviä tietoja ilman, että ihmisen tarvitsee lukea potilaan kertomuksia käsin. Kuitenkin potilaskertomuksia on vaikea mallintaa tekstin sotkuisuuden, monimuotoisuuden, monimerkityksellisten sanojen, epätäydellisyyden ja satunnaisten kirjoitusvirheiden vuoksi. Ihminen voi johdatella kertomuksen merkitystä kirjoitusvirheistä huolimatta, mutta tekstin sotkuisuus voi saada tietokoneen ohittamaan kliinisesti merkittävää tietoa tai jopa tekemään vääriä löydöksiä. Ihminen voi myös tulkita tekstiä rivien välistä, mikä jää tietokoneelta huomaamatta. Ennusteellisten ja tietoa poimivien tekstinlouhintaratkaisujen onnistuminen siis edellyttää oikeankaltaista tiedon poimintaa ja tekstidatan mallintamista, mikä on oleellinen osa tekstidatan esikäsittelyä.
Tekstin esikäsittely on keskeinen toimenpide tekstinlouhinnassa, missä teksti pilkotaan yksittäisiin sanoihin (tokenisointi), yksittäiset sanat muutetaan perusmuotoon (lemmatisointi) ja seulotaan sisällöltään merkityksettömät hukkasanat pois tekstistä. Näillä keinoin voidaan vähentää työstettävän tekstin määrää menettämättä paljoa tekstin tulkinnanvaraista merkitystä. Toisin sanoen tekstin esikäsittelyssä vähennetään ja yhdistetään muuttujia käsiteltävässä tekstidatassa, jotta tietokone voi prosessoida tekstiä tehokkaammin menettämättä tarkkuutta. Esikäsittely voi jopa tehdä tietokoneen suorittaman analyysin tarkemmaksi, kun epäoleellista tai jopa harhaanjohtavaa tietoa on poistettu tekstidatasta. Lisäksi tekstistä on helpompi louhia kliinisesti merkittävää tietoa, kun sanat on muutettu perusmuotoon, eikä sanojen taivutusmuotoja tarvitse erikseen ottaa huomioon.
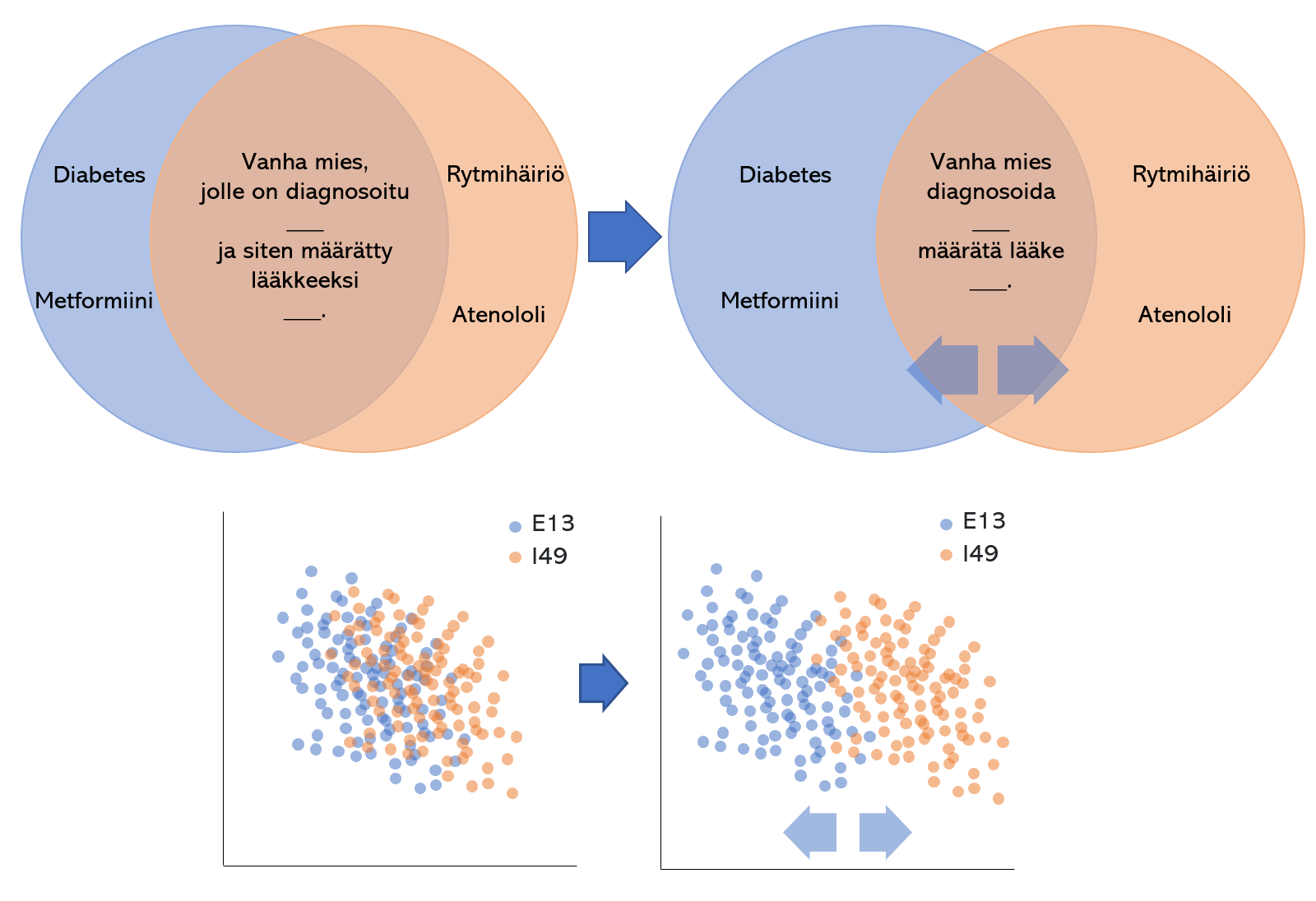
Tekstin esikäsittelyllä voidaan helpommin erottaa erilaiset tekstityypit toisistaan. Ensimmäisessä graafissa muutetaan tekstin sanat perusmuotoon ja poistetaan vähemmän merkittävät sanat, mistä seuraten tietokoneen on helpompi erottaa tekstidokumentit diagnoosien ja/tai lääkityksen perusteella. Pääkomponenttianalyysilla tuotettu pistekaavio, jossa kukin piste edustaa yhtä potilaskertomusta, näyttää kuinka eri diagnooseja sisältävien kertomuksien päällekkäisyys vähenee esikäsittelyn seurauksena.
Suomenkielisen tekstin prosessointiin, rikastukseen ja analysointiin on kehitetty lukuisia työkaluja, kuten Voikko, FiNER, UralicNLP ja TurkuNLP:n lukuisat ratkaisut. Näillä työkaluilla on mahdollista esikäsitellä, rikastaa, luokitella, tutkia ja löytää merkittäviä elementtejä suomenkielisestä tekstistä. Valmiiksi kehitettyjen työkalujen hyödyntäminen nopeuttaa ja suoraviivaistaa tutkimusta, mutta myös tekee tutkimuksesta helpommin toistettavan.
Tekstin rikastuksella voidaan lisätä tekstiin tietoa, joka voi auttaa ihmistä tai tietokonetta tekstin tulkinnassa tai merkittävien sanojen löytämisessä. FiNER:lla ja TurkuNLP:lla, tai termikirjastoilla voi rikastaa tekstiä, missä lisätään tekstin sanoille leimoja, jotka antavat sanoille lisämerkitystä, kuten ontologia, hierarkia, taivutusmuoto, jne. Kyseiset leimat voivat olla hyödyllisiä ennusteellisten koneoppimismallien opettamisvaiheessa, mutta myöskin tekstin tunnisteellisen tiedon peittämisessä. Usein tutkimukseen valmisteltava tekstidata voi sisältää tunnisteellista tietoa, mikä voidaan yhdistää yksittäiseen henkilöön. Sanoja tunnistavilla ja korostavilla työkaluilla on mahdollista peittää nämä tunnisteelliset tiedot tekstistä, jotta tekstiä ei voida yhdistää yksittäiseen henkilöön.

Esimerkki tekstin rikastuksesta ja pseudonymisoinnista synteettisellä tekstinäytteellä. Tässä esimerkissä sanoja on tunnistettu ja korostettu TurkuNLP:n Turku NER corpus-työkalulla. Yksittäiset sanat voidaan leimata ja korostaa tekstistä. Kuvassa henkilöiden nimet ovat korostettu punaisella, paikannimet sinisellä, mitat keltaisella ja muut purppuralla. Tunnistetut arkaluontoiset tiedot on sitten helppo korvata esimerkiksi pseudokoodilla. Samaa menetelmää voidaan myös hyödyntää kliinisesti merkittävän tiedon louhimisessa.
Tekstidokumenttien luokittelu on yksi keskeisistä tekstinlouhinnan haasteista. Lisäksi yhdellä potilaalla voi olla ajan suhteen useampia potilaskertomuksia ja jokaisen kertomuksen aikakonteksti on tärkeää tietoa potilaan fenotyypin määrittämisessä. Koodauksella, tai vektorisoinnilla rakenteeton tekstidata voidaan muuntaa tietokoneelle luettavaan rakenteiseen ja numeeriseen muotoon, kuten bag of words, Word2Vec tai one-hot vector muotoon, missä sanoja edustetaan niiden frekvenssiin, kontekstiin, tai nimeen perustuen. Rakenteiseksi ja numeeriseksi muutetuilla potilaskertomuksilla voidaan opettaa esim. takaisinkytkettyjä neuroverkkomalleja, jotka voivat ottaa aikakontekstin huomioon opetusprosessissa. Poimimalla kliinisesti merkittävää tietoa kertomuksista tekstinlouhintamenetelmillä ja muuntamalla tämä tieto aikakontekstuaaliseen vektorimuotoon, neuroverkkomallit kykenevät oppimaan ajan ja taudille altistavien tekijöiden yhteyden tietylle taudille sairastumisessa. Potilaskertomuksista louhittua tietoa voidaan myös yhdistää rakenteiseen terveysdataan laajempaa analyysia varten.
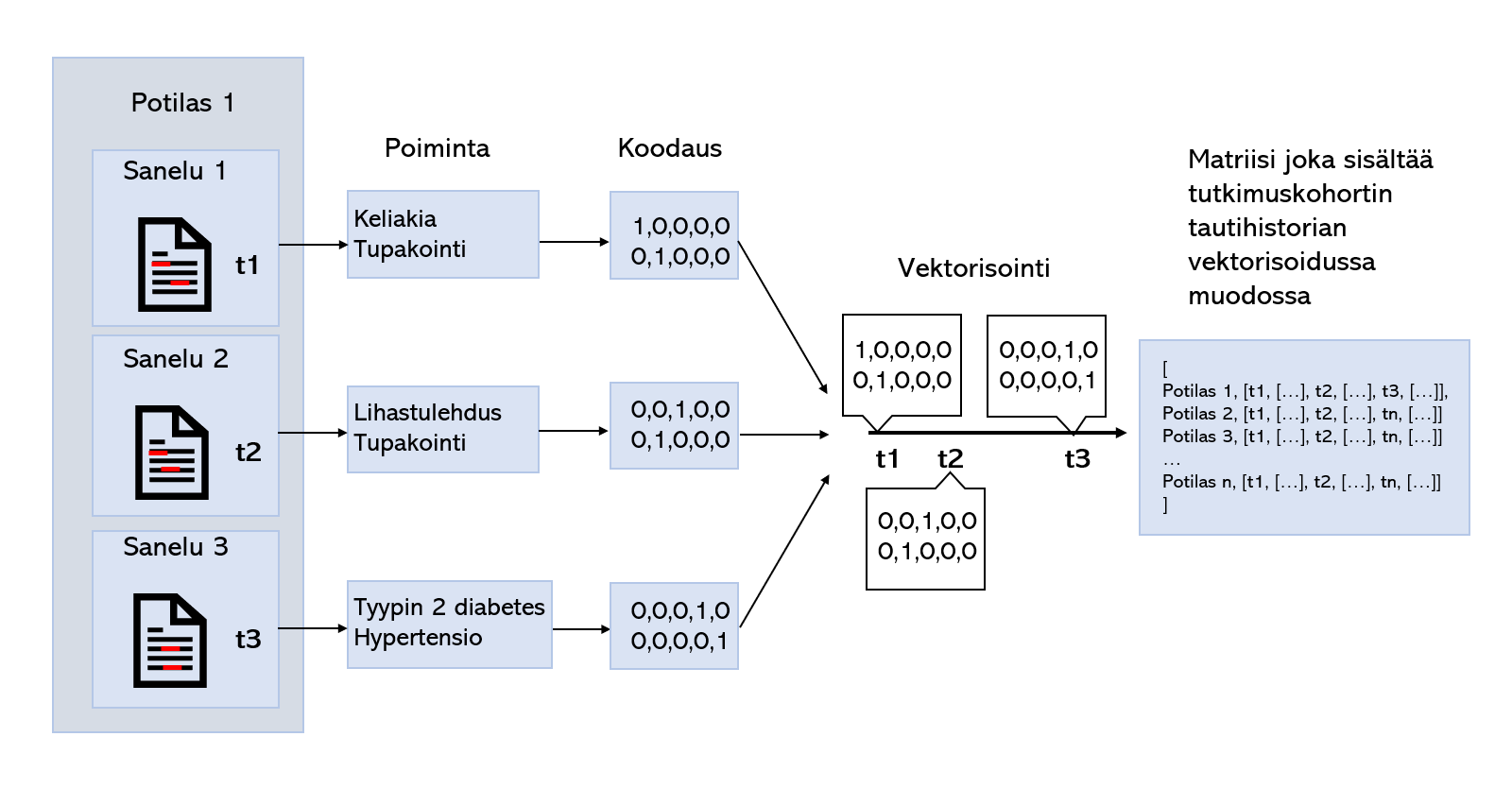
Sanakirjastoja ja opetettuja tekstinlouhintamalleja voidaan hyödyntää kliinisen tiedon louhinnassa kertomuksista. Jos halutaan opettaa ennusteellista koneoppimismallia louhitulla tiedolla, kyseinen tieto on muutettava numeeriseen muotoon.
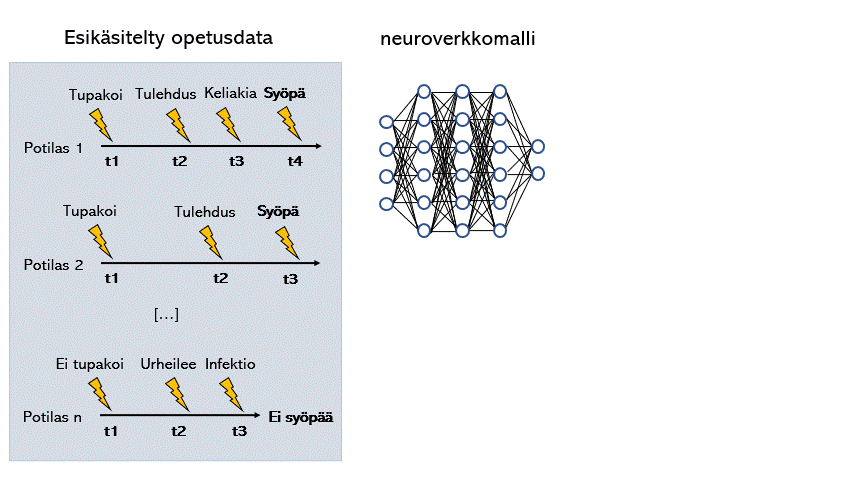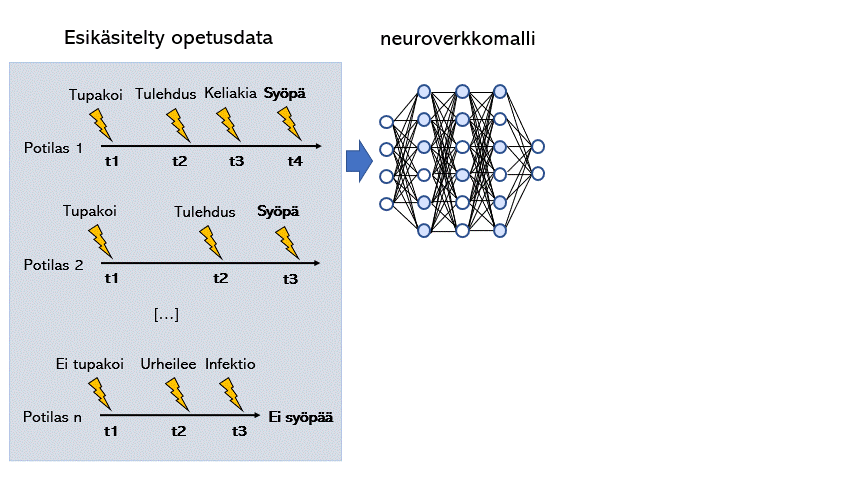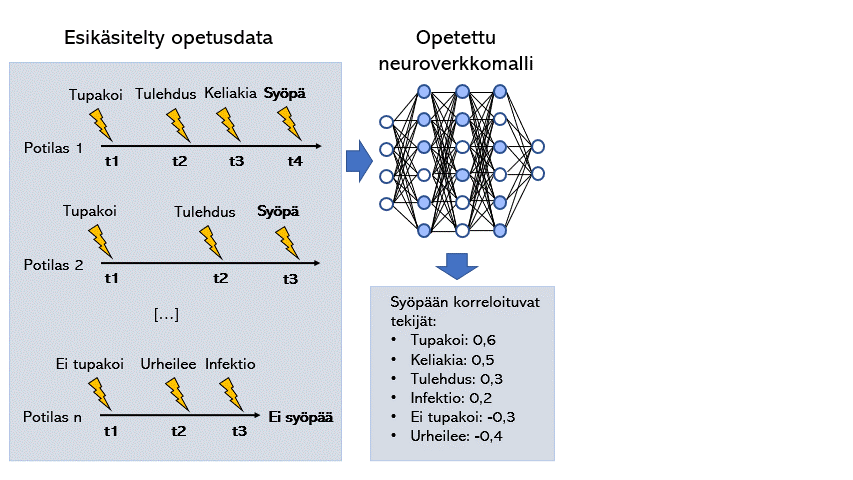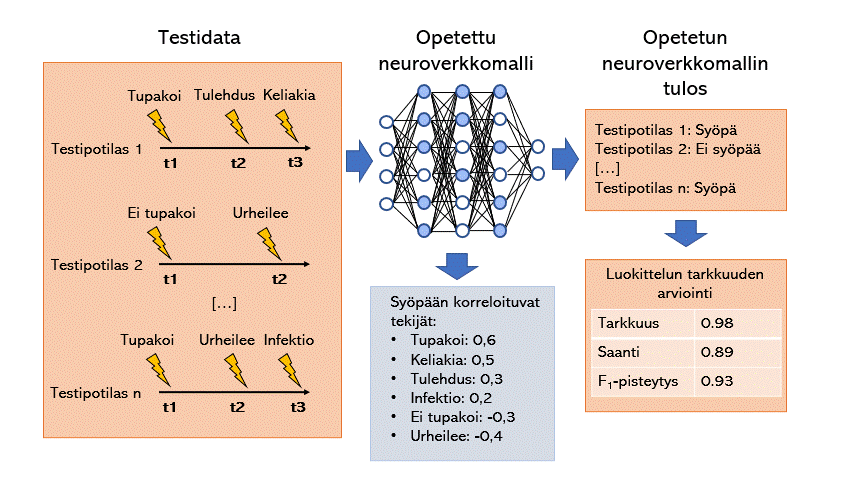
Koneoppimismalli (tässä esimerkissä neuroverkkomalli) voidaan opettaa luokittelemaan tietylle taudille riskialttiitta potilaita esittelemällä sille potilaskertomuksista louhittua tietoa. Koneoppimismalleilla on myös mahdollista tunnistaa taudille altistavia tekijöitä tulkitsemalla mitä painoarvoja millekin tekijälle koneoppimismalli antaa.
Tässä blogissa on pintapuolisesti käsitelty tekstinlouhinnan mahdollisuuksia ja haasteita. Tekstinlouhinnalla voidaan löytää potilaskertomuksista kliinisesti merkittävää tietoa, olivat ne sitten rakenteista tai rakenteetonta. Potilaskertomuksista louhittua tietoa voidaan hyödyntää sairauksille altistavien riskitekijöiden tunnistuksessa tai sairaudelle altistumisen ennustamisessa. Tekstinlouhintaratkaisut ovat kehittyneet sääntöpohjaisista malleista klassisiin koneoppimis- ja syväoppimismalleihin, jotka kykenevät tarkemmin tunnistamaan, rikastamaan ja ennustamaan kliinisiä ilmiöitä.
Syväoppimismallit vaativat suuremman aineiston ja niiden toiminta on vaikeammin selitettävissä neuroverkkojen ja moduulien monimutkaisuuksien vuoksi. Tutkimusta vahvasti rajoittava tekijä on potilaskertomuksien arkaluonteinen sisältö ja tekstin ”sotkuisuus”. Potilaskertomusten sotkuisuus vaatii paljon tekstin esikäsittelymenetelmien kehitystä, ennen kuin kertomukset ovat valmiita varsinaiseen tekstinlouhintaan. Potilaskertomuksien arkaluonteinen sisältö rajoittaa tutkijoiden pääsyä potilaskertomuksiin ja voi myös rajoittaa tutkimukseen annetun aineiston kokoa, rajoittaen syväoppimismallien opettamisen soveltuvuutta tutkimuksessa. Neuroverkoilla koulutettuja tekstinlouhintatyökaluja on julkisesti saatavilla, joilla voidaan tarkasti tunnistaa arkaluonteista tietoa potilaskertomuksista, mutta epäsuorat tunnisteelliset tiedot olisivat edelleen rajoittava tekijä.
Teksti: Simo Ryhänen, data-analyytikko, Itä-Suomen yliopisto, simo.ryhanen@uef.fi
AI-Hub Keski-Suomi ja Pohjois-Savo